Enterprise Data Warehouse on Snowflake
Project Overview
The organization had data spread across multiple operational systems including MySQL databases, CSV files, S3 storage, and external APIs. Reporting was slow, inconsistent, and involved heavy manual effort.
To address these challenges, I designed and implemented a modern Enterprise Data Warehouse (EDW) on Snowflake using a Bronze–Silver–Gold architecture with fully automated data pipelines.
This enabled real-time analytics, unified datasets, and fast, reliable Power BI dashboards.
Business Problems
The organization’s data was scattered across MySQL, S3, CSV files, and APIs, making reporting slow and inconsistent. An alysts relied on manual data preparation, leading to errors and delays. There was no unified, trusted source of truth for business decision-making.
Fragmented data sources- MySQL transactional system
- Raw logs and files in S3
- Vendor CSV files
- External APIs
- Different teams used different datasets
- inconsistent numbers
- Leadership could not rely on dashboards for accurate decision-making
- Daily Excel exports took hours and introduced errors
- Existing systems could not handle increasing data volumes
Solution Summary
I architected a scalable cloud data warehouse on Snowflake with automated ingestion, transformation, and data modeling. The solution unified data from multiple sources into a standardized Bronze–Silver–Gold structure. Automated workflows using Tasks and Stored Procedures ensured consistent, reliable processing. This enabled real-time, analytics-ready data for reporting and decision-making.
Key components of the solution- HEVO pipelines for ELT ingestion from all sources
- Madelian Snowflake architecture Bronze , Silver , Gold
- Scheduled Tasks and Stored Procedures for orchestration
- Dimension modeling (SCD-II) and surrogate keys
- Power BI dashboards for analytics consumption
- Governance, security, auditing
This enabled end-to-end automation across the entire data pipeline, eliminating manual processing and reducing operational overhead. Analytical datasets were refreshed continuously, ensuring timely and accurate insights for business users. As a result, stakeholders gained real-time access to consistent, trusted data for reporting and decision-making.
Architecture Overview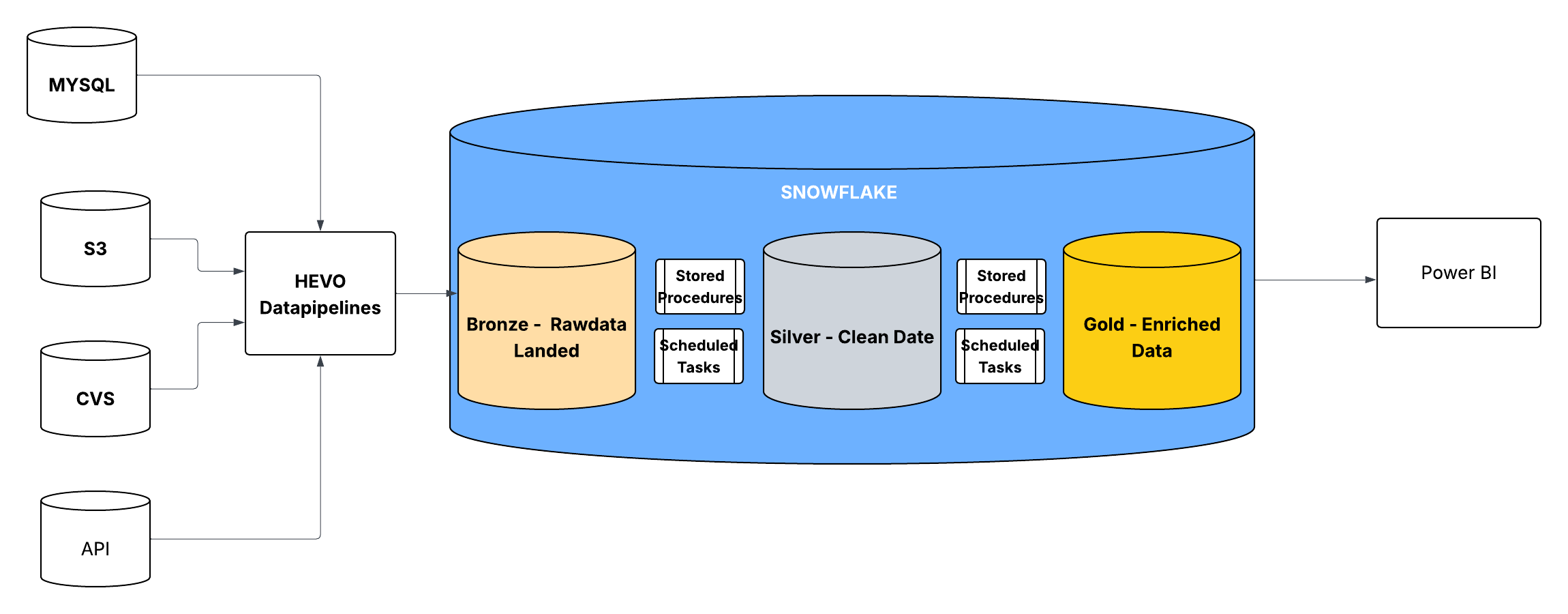
- Ingestion (HEVO) pulls data from MySQL, S3, CSV, and APIs
- Bronze Layer stores raw, unmodified data
- Silver Layer cleans, standardizes, and deduplicates
- Gold Layer creates analytical fact/dimension models
- Power BI reads from Gold for dashboards
Detailed Architecture Design
The architecture follows a structured Bronze,Silver,Gold data modeling approach to ensure clean, reliable, and analytics-ready data. Raw data from multiple sources is first landed in the Bronze layer, then standardized and transformed in the Silver layer, and finally enriched into business-friendly fact and dimension models in the Gold layer.
Automated Snowflake Tasks and Stored Procedures orchestrate the end-to-end data flow, ensuring consistency, scalability, and minimal operational overhead.
Ingestion Layer
Sources
- MySQL
- S3 logs and files
- CSV vendor data
- External API endpoints
- Near real-time ingestion
- Change Data Capture (CDC) from MySQL
- Schema evolution handling
- Built-in retry + error logging
Bronze Layer - Raw Landing Zone
- Preserve source data exactly as received
- Ensure data lineage and auditability
- Support reprocessing without hitting source systems
- No transformations
- Stores full historical snapshots
Silver Layer Clean & Standardized Data
- Data type normalization
- Date/time formatting
- Duplicate removal using window functions
- Null handling and defaulting
- Joining lookup reference data
- Generating surrogate keys
- Business-ready structured tables
- Standard naming conventions
- Ensures consistent reporting across domains
Gold Layer Business Enriched Models
Automation & Orchestration
- Handle multi-step ETL/ELT logic
- Reusable SQL + JS-based transformations
- Schedule incremental processing
- Run hourly/daily workflows
- Run error-handling procedures
- Logging tables
- Pipeline run history
- Alerting via custom notifications
Data Governance & Security
- Role-Based Access Control (RBAC)
- Masked View policies for PII fields
- Column-level security for sensitive attributes
- Row-level filtering for departmental access
- Warehouse cost optimization (auto-suspend, scaling policy)
- Data lineage documentation
Power BI Reporting Layer
Technologies Used
- Snowflake
- AWS S3
- HEVO Pipelines
- MySQL CDC
- API ingestion
- SQL
- Dimensional Modeling (Kimball)
- SCD Type-II
- Surrogate Key Generation
- Snowflake Tasks
- Stored Procedures
- Power BI
My Responsibilities
- Architecture design
- Ingestion setup via HEVO
- Bronze/Silver/Gold modeling
- Stored procedure development
- Scheduling with Snowflake Tasks
- Data quality & validation
- SCD-II & surrogate key logic
- Power BI integration
- Governance & security setup
- Performance tuning & cost optimization
Business Impact
- Reduced reporting time from 24 hours to under 15 minutes
- Eliminated manual Excel work for analytics teams
- Established a single, trusted source of truth
- Improved decision-making with real-time dashboards
- Increased data accuracy and reliability across departments
- Scalable architecture supporting future analytical and ML workloads
This project reflects my ability to design and deliver an enterprise-grade data platform that is scalable, fully automated, and aligned with governance and business needs. By modernizing the data ecosystem on Snowflake and standardizing the entire pipeline from ingestion to modeling and reporting—I enabled the organization to achieve real time insights, trusted data, and a sustainable foundation for advanced analytics and future ML workloads.